Why I’m still using redux and how I’m currently using redux.
One thing I’ve heard a lot recently, when other frontend people have taken a look at my code, is the question “Are you still using redux? That’s so wonderfully quaint and old fashioned. When we threw it out and started using useState() hooks our life got so much better!” (or maybe just “once we started using hooks our life got so much better”).
And yep, I am still using redux, even though react hooks, which supposedly made redux obsolete and old-fashioned, arrived back in 2018 (which is also the same year I started doing frontend programming).
In fact I’m using basically the same stack as when I doing started programming frontend in 2018, i.e. react, react-router, redux, saga and axios, but I’m using that stack very differently.
And for the record: I am using hooks a lot. I’m not completely retro. I just don’t use useState() or useEffect() much.
The main reason that I’m still using redux, can be summed up in the two words “redux devtool“.
There are actually other nice properties with redux, but without this devtool, I don’t think I would have bothered. Some of these properties, are:
- A consistent model for the data backing the GUI, that fits with my mental model of what’s going on
- It’s convenient to use redux actions for things not releated to the redux store (in my case: asynchronous network traffic and react-router navigation, for example it was the combination of redux actions and the react-router that gave me a simple way to implement navigation on swipe left and right, in 1990-ies picture archives in modern skin)
- Everything is inspectable, values aren’t hidden in black boxes
- I have found that I can make the data model reflect any desired behaviour (i.e. retain data across views is possible, retain some data and transform other values is possible, clear data across views is possible, and it’s easy to adjust between different behaviours. You are not locked in to the local state someone decided to put into a component)
- Encourages a data-centric view of the application: I know that once I can make the data change as expected the changed values will be rendered automagically, so I focus on getting the data right
- Some things are just plain easy, like the way I’m doing i18n/i10n. It’s very easy to swap display language and have it taken care of everywhere
- I don’t see much need for things like typescript, because my redux stores mostly store primitive values and I see pretty quickly in the redux devtool if they get the wrong type (typically if they become a string instead of a number, or null where it should have been an empty string)
- The way things are nicely re-rendered when the data in redux is updated, i.e. it’s possible to enter a component before the required data is in place, requesting the data as you enter the component, and then have the component update automagically when data arrives
I have used many model/view GUI concepts over the years, but react/redux is by far the one that has worked best.
I mentioned earlier, that I am using the same stack as in 2018, but using it differently. And the places where I’m now using the react, react-router, redux, saga and axios stack differently, are:
- The redux store state used to be narrow and deep, now it is wide and shallow
- Reducers used to be complex (to handle replacing data deep down in hierarchial data structures), now reducers are trivial (mostly just replacing the current state with action.payload)
- I used to reuse redux actions across components, if the actions carried the same payload and ended up in the same reducers, now I give each unique action source its own action, mentioning the GUI component in the action type name, e.g. “FOO_BUTTON_CLICKED” and “BAR_FIELD_MODIFIED”. If there is only one source of an action, it’s much easier to track down what causes a particular redux store state change. And if the source is part of the action name, it’s even easier to track the source
- Code related with what to display and composing REST request objects used to be spread across reducers, react components and sagas, now all of this logic resides in sagas
- I used to use class react components with componentDidMount() dispatching redux actions that triggered the loading of data necessary for that component, now I use a saga listening to react-router changes and firing off the relevant redux actions starting data load, when entering a given react-router location (I have looked into using useEffect() instead, but found it as flaky and unpredictable as componentDidMount() and have stayed with the locationSaga practice)
- React components used to be class components, with lots of non-render logic in the componentDidMount() methods, in the render() methods and in the dispatch methods, now they are all functional components, containing only the JSX rendering and useSelector() and useDispatch() hooks to use and set data in the redux store (in place of useState())
- I used to preserve the structure of data as received, so that it always was in the state it should be sent back over the wire to the backend, complicating the reducers and the components, but simplifying the sagas, now data is flattened in the reducers (see “wide and shallow” redux store state above) and a saga will collect the values to create the structure to be POSTed to a REST endpoint
- The connect() and mapState() and mapDispatch() functions used to connect react components to redux, has been replaced with useSelector() and useDispatch() hooks
As I said, my main reason for still be using redux, is the redux devtool. This devtool exists for firefox, edge and chrome, and in chrome, it looks like this:
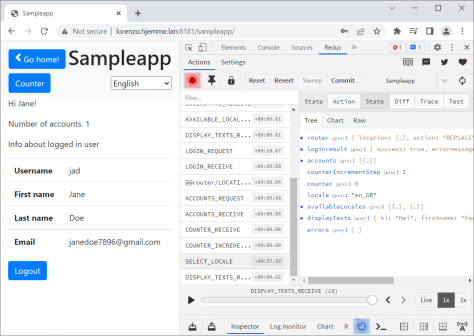
The screenshot shows the redux devtool occupying the right half of the browser window, with the application being debugged using the left half.
The vertical list in the redux devtool, is a list of redux actions in chronological order.
It is possible to go up and down in that list, and examine the redux store state at any given point in time, as well as looking at the diff of the state between the previous action and the current selection, and also look at what the payload looks like. This makes it easy to pinpoint what action modifies the examined value and why it is changed.
And since I now follow a pattern where each redux action source gets its own action (not “reusing” actions that happen to have the same payload and end up in the same reducers), it is easy to see where the data that changed the redux state originated from.
One reason I have heard people give for abandoning redux, is that there is “too much seremony”, too much code in too many files that needs to be changed when making changes to the datamodel.
And I agree with that. Especially using connect() with mapStateToProps() and mapDispatchToProps() is cryptic. And with a deep and nested redux structure the mapStateToProps() functions become complicated and fragile and a hard-to-debug point of failure.
Even with a flat redux structure and a simple mapStateToProps(), if I add a redux store state variable to a component that already has a long list of redux state variables, I typically need to make the addition three places
- In mapStateToProps() when picking variables out of the redux store
- In mapStateToProps() when building up the object to add to props
- In the component render method when picking the variables out of the props
E.g. like this:
function SomeComponent(props) {
const {
var1,
var2,
var3,
onChange1,
onChange2,
onChange3,
onSubmit,
} = props;
return (
<div>
<form onSubmit={ e => { e.preventDefault(); }}>
<div>Var1: <input value={var1} onChange={onChange1}/></div>
<div>Var2: <input value={var2} onChange={onChange2}/></div>
<div>Var3: <input value={var3} onChange={onChange3}/></div>
<button onClick={onSubmit}>Submit</button>
</form>
</div>
);
}
function mapStateToProps(state) {
const {
var1,
var2,
var3,
} = state;
return {
var1,
var2,
var3,
};
}
function mapDispatchToProps(dispatch) {
return {
onChange1: e => dispatch(VAR1_FIELD_MODIFIED(e.target.value)),
onChange2: e => dispatch(VAR2_FIELD_MODIFIED(e.target.value)),
onChange3: e => dispatch(VAR3_FIELD_MODIFIED(e.target.value)),
onSubmit: () => dispatch(SUBMIT_FORM()),
};
}
export default connect(mapStateToProps, mapDispatchToProps)(SomeComponent);
Since this becomes messy with just three variables, imagine what it looks like with 15 variables, all with similar names.
Also filling up the props list with a similar number of dispatch functions, to set the values, in redux state, doesn’t help readability and maintainability, either.
Luckily, thanks to the existance of redux hooks, this can now be made far more compact and readable:
export default function SomeComponent() {
const var1 = useSelector(state => state.var1);
const var2 = useSelector(state => state.var2);
const var3 = useSelector(state => state.var3);
const dispatch = useDispatch();
return (
<div>
<form onSubmit={ e => { e.preventDefault(); }}>
<div>Var1: <input value={var1} onChange={e => dispatch(VAR1_FIELD_MODIFIED(e.target.value))}/></div>
<div>Var2: <input value={var2} onChange={e => dispatch(VAR2_FIELD_MODIFIED(e.target.value))}/></div>
<div>Var3: <input value={var3} onChange={e => dispatch(VAR3_FIELD_MODIFIED(e.target.value))}/></div>
<button onClick={() => dispatch(SUBMIT_FORM())}>Submit</button>
</form>
</div>
);
}
The props list is now just used for props set by the parent, so those components that don’t have props set by the parent won’t need a list.
Also this approach makes it simple to convert to useState() hooks if that is to be desired, or to go from useState() to redux.
The other place where I myself, initially had a lot of complicated code, were the reducers.
This was partly because of the deep nested data model used in the redux store (i.e. the same thing that complicated the mapStateToProps() functions), but also because writing reducers as switch statements where cumbersome and fragile (don’t ever forget to always return state on unchanged state!).
But redux-toolkit has simplified creating reducers (and redux actions) considerably.
Where an “old style reducer” would look something like this:
const initialState = {
foo: '',
bar: 0,
};
function foobarvalue(state = initialState, action) {
switch(action.type) {
case 'FOO_INPUT_MODIFIED': {
return { ...state, bar: action.payload };
}
case 'BAR_INPUT_MODIFIED': {
return { ...state, foo: parseInt(action.payload) };
}
case 'RESET_FOOBAR': {
return { ...initialState };
}
default:
return state; // If you forgot this in a reducer, bad things would happen
}
}
in redux-toolkit style reducers, I first define constants for each action like this, using the createAction() function:
export const FOO_INPUT_MODIFIED = createAction('FOO_INPUT_MODIFIED');
export const BAR_INPUT_MODIFIED = createAction('BAR_INPUT_MODIFIED');
export const RESET_FOOBAR = createAction('RESET_FOOBAR');
and then I create separate reducers for each primitive value, using the createReducer() function, i.e. one reducer for foo:
const initialState = '';
const fooReducer = createReducer(initialState, {
[FOO_INPUT_MODIFIED]: (state, action) => action.payload,
[RESET_FOOBAR]: () => initialState,
};
and another reducer for bar:
const initialState = 0;
const barReducer = createReducer(initialState, {
[BAR_INPUT_MODIFIED]: (state, action) => parseInt(action.payload),
[RESET_FOOBAR]: () => initialState,
};
The first thing to note is that the default switch, returning the state, isn’t necessary to specify, because the correct default behaviour is set up in the reducer created by the createReducer() function.
It’s possible to have a redux-toolkit reducer storing values in an object like what’s done in the old-style reducer example. But it doesn’t require much experimentation to see that splitting things into primitive values in the reducers gives the simplest and most predictable behaviour.
It is simpler to handle empty values, there is no problems with react components not being re-rendered, and no problem getting excessive rerendering because the parent object has changed, but the individual values haven (i.e. no need for memoization for performance reasons), and it’s easy to see that variables have the correct type in the redux devtool (less incentive to use something like typescript).
It is also simpler to keep reducers as compact one-liners, because the reducers have less work to do. Most of my reducer action handlers just replace the current state with action.payload.
The actions created by the createAction() function serves both as action selectors in the reducer, and as constructor functions in the dispatch methods, e.g. like this:
<div>Var1: <input value={foo} onChange={e => dispatch(FOO_FIELD_MODIFIED(e.target.value))}/></div>
The FOO_FIELD_MODIFIED(e.target.value) function will return an object like this:
{
type: 'FOO_FIELD_MODIFIED',
payload: e.target.value,
}
Using a constructor to create the actions keeps the actions consistent and using the same name on the constructor as the action itself, simplifies debugging and reading code.
One thing that is similar to when I started frontend programming, is the react-router and my usage of the react-router
When I write a webapp, my mental model and mindset is “create a website”, rather than “emulate a thick client GUI”.
Because of this, I’ve adopted react-router and its way of thinking, in that different components are represented by different local paths in the URL, and that the URL changes as you navigate between react components, and that its possible to reload the URL and be able to return to that component in a meaningful state.
I’m also using something called connected-react-router that connects the react-router to redux.
This means that there will be actions in redux when you navigate in the react-router, by whatever means.
And this means that you can navigate in your appliation by firing redux action.
I take advantage of both:
- My webapps have a saga that listens to navigational changes, and triggers loading of fresh data from the backend, when locations that needs the data are entered. This was formerly handled with varying degrees of success using componentDidMount() in class components, and also with varying degrees of success, using the useEffect() hook. But I’ve found having a locationSaga to the job to be simpler and have less surprising behaviour
- In the implementation of swipe left and right in 1990-ies picture archives in modern skin I dispatch connected-react-router redux actions to navigate to a neighbour album or image when swiping
The people behind react-router don’t like redux much, but I wouldn’t like to be without connecting the two. And I think they are focusing on the wrong thing in their criticism: the react-router redux connection, for me, is not about having the router state in the redux store state. It is about using redux actions to signal, and initiate, navigation.
When I initially started using react and redux, sagas were only used for asynchronous REST communication. And that worked especially well in combination with redux’s “redraw when is updated” behaviour.
Specifically, one could just trigger the load of fresh data when entering a component that needs it, and start rendering the component with the current data, and the component would automagically redraw when fresh data arrived.
I tried doing REST requests without involving redux in one of my projects, but I found that I missed the asynchronous “fire and forget” behaviour of just triggering load and then not concerning myself with what was happening, so I ended up putting sagas back.
But now I’m using sagas for something else, which is logic that involves more than one redux value.
Logic that formerly resided in react components render methods and looked at multiple redux values to determine if a component should be displayed or not, has been moved into sagas that listen for changes to the involved redux values, and writes a flag to redux saying whether the component should be displayed or not, so this flag is all the component have to look at to determine if it should be displayed or not.
If you wish to create a library of high level react components and you wish to encapsulate a lot of behaviour inside the components, then you probably should use useState() instead of redux.
Personally I’m thinking that creating such a library probably isn’t a great idea, because in my experience one often thinks one wants the same behaviour in different places, but there are always subtle differences that needs adjustments and configuration and changes, and the encapsulated the components are, the harder they will be to fit everywhere.
I have heard some people say that you should use redux on large applications and useState() on small applications, but that have never made sense to me. It makes sense to me to use redux with react, and the size of the application really doesn’t matter.
The place where I’m currently is using useState() is in login dialogs. The fact that username and password aren’t stored in the redux store is actually a feature here.
I tried out a hybrid approach of storing intermediate values with useState(), to avoid spamming the action stream with small edit actions. That worked fine until I wanted to reset the form. I was told “you need to use useEffect() for that”, i.e. not so easy. So I dropped the hybrid attempt and went back to pure redux.
So in conclusion: thanks to the existence of redux-toolkit and redux hooks, redux is much simpler to use today than its reputation would indicate, and has a real nice debugging tool.
Just remember to:
- Don’t store anything in the redux store you don’t actually need
- Use redux-toolkit to set up redux, and to create reducers and redux actions
- Keep the redux store structure shallow and wide, and not narrow and deep (or even worse: wide and deep, with the same data in several places). If the state gets too wide to navigate comfortably in, consider splitting the frontend up into several smaller frontends
- Use the useSelector() and useDispatch() hooks in react components (preferrably function components)
- Put all logic involving multiple reducer values into sagas (keep it out of react components)

One thought on “Yep, I’m still using redux”